阅读材料 3 - 测试 | MIT 6.005
MIT 6.005 Spring 2016 的 OCW 版本的学习笔记。此篇笔记涉及的内容为 Reading 3 Testing。
课程目标
上完今天的课程后,你应该:
- 了解测试的价值,知道测试优先的编程过程;
- 能够通过划分输入和输出空间以及选择好的测试用例来为方法设计测试套件;
- 能够通过测量代码覆盖率来判断测试套件;
- 了解并知道何时使用黑盒(blackbox)测试与白盒(whitebox)测试、单元(unit)测试与集成(integration)测试,以及自动回归(automated regression)测试。
验证 Validation
测试是名为 验证 的一般过程的一种典型例子。验证的目的是发现程序中的问题,从而增强对程序正确性的信心。 验证包括:
- 对程序进行形式推理,通常称为 Verification。 Verification 构建了程序正确性的形式化证明。使用手工方法进行 Verification 非常繁琐,而相关自动化工具仍处于活跃的研究中。不过,程序中的一些小的关键部分可以进行正式验证,例如操作系统中的调度程序、虚拟机中的字节码解释器或操作系统中的文件系统。
- 代码审查(Code Review)。 让别人仔细阅读你的代码,并对其进行非正式推理,是发现错误的好方法。这就像让别人校对你写的文章一样。我们将在下一篇文章中详细介绍代码审查。
- 测试。在精心挑选的输入上运行程序并检查结果。
即使进行了最好的验证,也很难达到完美的软件质量。 以下是一些典型软件的每千行代码残余缺陷数量:
- 1 - 10 个缺陷:典型工业软件。
- 0.1 - 1 个缺陷:高质量验证。Java 库也许达到了这种程度的正确性。
- 0.01 - 0.1 个缺陷:最好的、严格安全的验证。NASA 和 Praxis 这样的公司可以达到这一水平。
对于大型系统来说,这可能很打击人。例如,如果您交付的典型工业软件代码大约有一百万行,那您可能遗漏了 1000 个错误!
为什么软件测试很困难
不幸的是,在软件世界中,有些方法并不奏效。
穷举测试 (Exhaustive Testing) 是不可行的。可能的测试用例空间通常太大,无法穷尽覆盖。试想一下,穷举测试 32 位浮点乘法运算
杂乱无章的测试 (Haphazard Testing) (“试一试,看能不能用”)不太可能发现错误,除非程序漏洞百出。任意选择的输入更有可能失败,而不是成功。它也不会增强我们对程序正确性的信心。
随机测试或统计测试 (Random or Statistical Testing) 对软件并不适用。 其他工程学科可以测试随机的小样本(如生产的硬盘驱动器的 1%),并推断出整个生产批次的缺陷率。 物理系统可以使用许多技巧来加快时间,比如在 24 小时内打开冰箱 1000 次,而不是 10 年。这些技巧给出了已知的故障率(如硬盘驱动器的平均寿命),但它们假定了缺陷空间的连续性或一致性。 这对物理工件来说是正确的,但对软件来说并非如此。
软件的行为在可能的输入空间内是不连续和离散变化的。在广泛的输入范围内,系统可能看似运行正常,但在某个边界点却突然失灵。著名的奔腾除法错误大约影响了 90 亿次除法中的 1 次。堆栈溢出、内存出错和数值溢出错误往往会突然发生,而且总是以同样的方式发生,而不是以概率变化的方式发生。 这与物理系统不同,在物理系统中,经常有明显的证据表明系统正在接近故障点(桥梁上的裂缝),或者故障在故障点附近呈概率分布(因此统计测试甚至在故障点到达之前就能观察到一些故障)。相反,软件测试中的测试用例必须谨慎、系统地选择,这就是我们接下来要研究的内容。
成为一个软件测试人员
测试需要有正确的态度。当你编码时,你的目标是让程序运行,但作为测试人员,你的目标是让它失败。这是一个微妙但重要的区别。把刚写好的代码视为珍宝、易碎的蛋壳,轻描淡写地测试一下就想让它正常工作,这种做法太诱人了。但是,你必须残酷无情。好的测试人员会挥舞大锤,敲打程序可能存在漏洞的地方,从而消除这些漏洞。
测试优先编程 Test-first Programming
尽早测试,经常测试。不要把测试留到最后,当你有一大堆未经验证的代码时才进行。把测试留到最后只会让调试变得更漫长、更痛苦,因为错误可能就在代码的任何地方。在开发过程中测试代码会让人愉快得多。
在测试优先编程中,在编写任何代码之前都要先编写测试。一个函数的开发过程是这样的:
- 为函数编写规范 (Specification)。
- 编写测试来验证规范。
- 编写实际代码。一旦代码通过了测试,就大功告成了。
规范 (Specification) 描述了函数的输入和输出行为。它给出了参数的类型以及对参数的附加限制(例如,sqrt 函数的参数必须非负)。它还给出了返回值的类型以及返回值与输入的关系。您已经在本课的问题集中看到并使用过规范。在代码中,规范由方法签名(method signature)和上面的注释组成,注释描述了方法的作用。关于规范,我们将在以后的几节课中详细介绍。
优先编写测试是理解规范的好方法。规范也可能有缺陷 —— 不正确、不完整、模棱两可、遗漏边界条件 (corner cases)。尝试编写测试可以及早发现这些问题,避免浪费时间编写错误规范的实现。
通过划分来选择测试用例
创建一个好的测试套件是一个具有挑战性且有趣的设计问题。我们希望挑选一组测试用例,它们既要小到足以快速运行,又要大到足以验证程序。
为此,我们将输入空间划分为多个 子域 (Subdomains),每个子域由一组输入组成。这些子域加在一起完全覆盖了输入空间,因此每个输入至少位于一个子域中。然后,我们从每个子域中选择一个测试用例,组成我们的测试套件。
子域背后的理念是将输入空间划分为相似的输入集,程序在这些输入集上具有相似的行为。然后,我们使用每个集合中的一个代表。这种方法通过选择不同的测试用例,迫使我们的测试探索随机测试可能无法达到的输入空间部分,从而充分利用了有限的测试资源。
如果我们需要确保测试能够探索输出空间的不同部分,也可以将输出空间划分为子域(程序具有相似行为的相似输出)。但在大多数情况下,对输入空间进行划分就足够了。
例子:BigInterger.multiply()
让我们来看一个例子。BigInteger 是一个 Java 库中的内置类。它可以表示任意大小的整数,而不是像原始数据类型 int 和 long 那样只能表示有限数据范围的整数。大整数有一个 multiply 方法用于对两个 BigInteger 相乘:
/**
* @param val another BigIntger
* @return a BigInteger whose value is (this * val).
*/
public BigInteger multiply(BigInteger val)
例如,可以这样使用它:
BigInteger a = ...;
BigInteger b = ...;
BigInteger ab = a.multiply(b);
这个例子表明,尽管在方法的声明中只明确显示了一个参数,但 multiply 实际上是两个参数的函数:调用方法的对象(上例中的 a)和在括号中传递的参数(上例中的 b)。在 Python 中,接收方法调用的对象会在方法声明中被明确命名为名为 self 的参数。 而在 Java 中,我们不会在参数中提及接收对象,并且它被称为 this 而不是 self。
因此,我们应将 multiply 视为一个函数,它接受两个输入,每个输入都是 BigInteger 类型,并产生一个 BigInteger 类型的输出:
因此,我们有一个二维输入空间,由所有整数对
a和b都是正数a和b都是负数a是正数,b是负数a是负数,b是正数
我们还应该检查一些乘法的特殊情况:
a或b是, 或
最后,作为一个试图找出 bug 的测试人员,我们可能会怀疑 BigInteger 的实现者可能会在可能的情况下通过在内部使用 int 或 long 来使其更快,只有在值太大时才使用昂贵的一般表示(如数字列表)。因此,我们肯定也应该尝试使用非常大的整数,比最大的 long 整数还要大。
a或b很小a或b的绝对值大于Long.MAX_VALUE,即 Java 原始数据类型的最大正数(大约为)
综上,对于整个 a 和 b:
- 小正整数
- 小负整数
- 大正整数
- 大负整数
这产生了
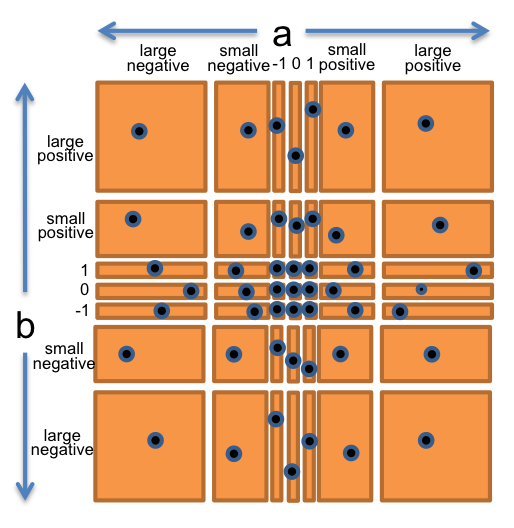
为了创建测试套件,我们可以从网格的每个方格中任意选取一对
覆盖(小负数,小正数) 覆盖(0,小正数) 覆盖(大整数,1) - 等等
下图展示了上面的划分,图中标出的点可能就是我们选择的完全覆盖该分区的测试用例:
例子:max()
让我们看看来自 Java 库中的另一个函数,来自 Math 类中的 max() 函数。
/**
* @param a an argument
* @param b another argument
* @return the larger of a and b.
*/
public static int max(int a, int b)
从数学上,该函数遵循:
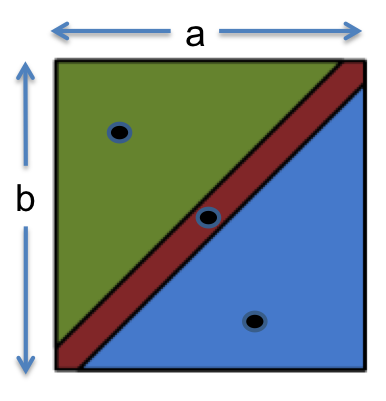
从这样的规范中,我们可以将函数分划为:
我们的测试套件可以是:
用于覆盖 的情况 用于覆盖 的情况 用于覆盖 的情况
在分区中包含边界
Bugs 通常发生在子域的 边界。例如:
是边界,正数和负数的边界 - 数据类型(例如
int和double)的最大值或最小值是边界 - 空(空字符串、空列表、空数组)是集合类型的边界
- 集合类型的第一个和最后一个元素是边界
为什么错误经常发生在边界处?其中一个原因是程序员经常犯 差一错误 (off-by-one mistakes)(如将 <= 写成 < ,或将计数器初始化为 0 而不是 1)。另一个原因是,有些边界可能需要在代码中作为特例处理。又或者,边界可能是代码行为中的不连续处。例如,当一个 int 变量的增长超过其最大正值时,它就会突然变成一个负数。
重要的是,要将边界作为子域纳入分区,以便从边界中选择输入。
重新对
- 考虑
与 的关系 - 考虑
的值 为最小整数 为最大整数
- 考虑
的值 为最小整数 为最大整数
现在,我们可以选择覆盖这些类别的测试数据了:
覆盖 的情况 覆盖 的情况 覆盖 的情况 (Integer.MIN\_VALUE, Interger.MAX\_VALUE)覆盖的情况 (Integer.MAX\_VALUE, Interger.MIN\_VALUE)覆盖的情况。
覆盖分区的两个极端
对输入空间进行划分后,我们可以选择测试套件的彻底程度:
- 全笛卡尔乘积(Full Cartesian product)。每一个分割维度的合法组合都有一个测试用例。 我们在乘法示例中就是这样做的,结果得到了
个测试用例。对于包含边界的最大值示例,它有三个维度,分别为 3 部分、5 部分和 5 部分,这意味着多达 3 × 5 × 5 = 75 个测试用例。 但实际上,并非所有这些组合都是可能的。例如,无法覆盖 这样的组合,因为 a 不可能同时小于零和等于零。 - 覆盖每个部分。 每个维度的每个部分都至少有一个测试用例,但不一定是每个组合。采用这种方法,如果精心选择,
max的测试套件可能只有 5 个测试用例。
通常,我们会在这两个极端之间做出一些折中,基于人为的判断和谨慎,并且受到白盒测试和代码覆盖工具的影响,我们将在下文中探讨这些主题。
黑盒与白盒测试
回顾上文,规范 是对函数行为的描述 ——参数类型、返回值类型以及它们之间的约束和关系。
黑盒测试 意味着仅从规范中选择测试用例,而不是函数的实现。这就是我们迄今为止在示例中一直在做的。我们在不查看multiply 和 max 函数实际代码的情况下,对这些函数进行了分区并寻找边界。
白盒测试(也称为玻璃盒测试)是指在了解函数实际实现方式的情况下选择测试用例。例如,如果函数的实现会根据输入选择不同的算法,那么就应该根据这些域进行划分。 如果实现保留了内部缓存,可以记住以前输入的答案,那么就应该测试重复输入。
在进行白盒测试时,必须注意你的测试用例不应 要求 规范中没有明确要求的特定实现行为。例如,如果规范说 “如果输入格式不正确,就会抛出异常”,那么你的测试就不应该仅仅因为当前实现抛出 NullPointerException 就专门检查这样特定类型的异常。因为在这种情况下,规范允许抛出任何异常,所以你的测试用例同样应该是通用的,以保留实现者的自由。关于这一点,我们将在 “规范” 课程中详细介绍。
将你的测试策略写入文档
对于下面的示例函数:
/**
* Reverses the end of a string.
*
* For example:
* reverseEnd("Hello, world", 5)
* returns "Hellodlrow ,"
*
* With start == 0, reverses the entire text.
* With start == text.length(), reverses nothing.
*
* @param text non-null String that will have
* its end reversed
* @param start the index at which the
* remainder of the input is
* reversed, requires 0 <=
* start <= text.length()
* @return input text with the substring from
* start to the end of the string
* reversed
*/
static String reverseEnd(String text, int start)
我们可以这样记录上述分区练习中的分区策略。该策略还解决了一些我们之前没有考虑到的边界值问题。
在测试类的顶部记录策略:
/*
* Testing strategy
*
* Partition the inputs as follows:
* text.length(): 0, 1, > 1
* start: 0, 1, 1 < start < text.length(),
* text.length() - 1, text.length()
* text.length()-start: 0, 1, even > 1, odd > 1
*
* Include even- and odd-length reversals because
* only odd has a middle element that doesn't move.
*
* Exhaustive Cartesian coverage of partitions.
*/
记录下如何选择每个测试用例,包括白盒测试:
// covers test.length() = 0,
// start = 0 = text.length(),
// text.length()-start = 0
@Test public void testEmpty() {
assertEquals("", reverseEnd("", 0));
}
// ... other test cases ...
覆盖率
评判测试套件的一种方法是看它对程序进行了多彻底的测试。这一概念称为覆盖率。以下是三种常见的覆盖范围:
- 语句覆盖:每条语句都被测试用例覆盖到了吗?
- 分支覆盖:对于程序中的每个
if或while语句,测试用例是否都覆盖了 true 和 false 两种情况? - 路径覆盖:对于每个可能的分支组合 —— 即程序的每条路径 —— 都由特定的测试用例覆盖到了?
分支覆盖率指标强于语句覆盖率指标(因为它需要更多的测试代码才能实现),而路径覆盖率指标也强于分支覆盖率指标。行业中,100% 的语句覆盖率是一个常见的目标,但由于防御性代码(如 “永远不应到达此处” 的断言)无法达到,即使是这样的目标也很少能实现。 100% 的分支覆盖率是非常理想的,而对安全至关重要的工业代码则有更苛刻的标准(如 “MCDC”,修改后的决策/条件覆盖率)。遗憾的是,100% 的路径覆盖是不可行的,需要指数级大小的测试套件才能实现。
测试的标准方法是:增加测试,直到测试套件达到足够的语句覆盖率,即程序中的每一条可触及语句都至少被一个测试用例执行。在实践中,语句覆盖率通常由代码覆盖率工具来衡量,该工具会计算测试套件运行每条语句的次数。有了这种工具,白盒测试就很容易了;你只需测量黑盒测试的覆盖率,然后添加更多测试用例,直到所有重要语句都被记录为已执行。
下图所示的 EclEmma 是一款适用于 Eclipse 的优秀代码覆盖工具。
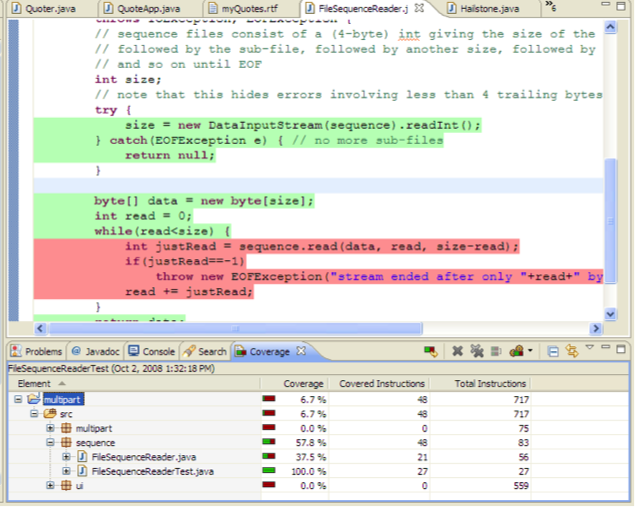
测试套件已执行的行显示为绿色,尚未覆盖的行显示为红色。如果您从覆盖工具中看到了这样的结果,那么下一步就是编写一个测试用例,使 while 循环的主体执行,并将其添加到测试套件中,这样红行就会变成绿行。
单元测试和存根
一个经过良好测试的程序会对其包含的每个模块(模块是指方法或类)进行测试。如果可能,对单个模块进行隔离测试的测试称为单元测试。 对模块进行隔离的测试可以大大简化调试工作。当某个模块的单元测试失败时,你可以更确信错误是在该模块中发现的,而不是在程序的任何地方。
与单元测试相反的是集成测试,它测试模块的组合,甚至整个程序。如果只有集成测试,那么当测试失败时,就必须寻找错误。它可能出现在程序的任何地方。集成测试仍然很重要,因为程序可能会在模块之间的连接处出现故障。例如,一个模块期望的输入可能与实际从另一个模块获得的不同。但是,如果你有一套完整的单元测试,让你对各个模块的正确性有信心,那么你就可以少走很多弯路,找到错误所在。
假设你正在构建一个 Web 搜索引擎。你可能一个 getWebPage() 模块用于下载 Web 页面,以及一个 extractWords() 模块用于将页面拆分为单词:
/** @return the contents of the web page downloaded from url
*/
public static String getWebPage(URL url) {...}
/** @return the words in string s, in the order they appear,
* where a word is a contiguous sequence of
* non-whitespace and non-punctuation characters
*/
public static List<String> extractWords(String s) { ... }
这些方法可能会被另一个 makeIndex() 模块使用,作为制作搜索引擎索引的网络爬虫的一部分:
/** @return an index mapping a word to the set of URLs
* containing that word, for all webpages in the input set
*/
public static Map<String, Set<URL>> makeIndex(Set<URL> urls) {
...
for (URL url : urls) {
String page = getWebPage(url);
List<String> words = extractWords(page);
...
}
...
}
在我们的测试组件中,我们希望:
- 对
getWebPage()进行单元测试,测试不同的 URLs - 对
extractWords()进行单元测试,测试不同的字符串 - 对
makeIndex()进行单元测试,测试不同的 URLs 集合
程序员有时会犯的一个错误是,在编写 extractWords() 的测试用例时,测试用例依赖于 getWebPage() 的正确性。最好是单独考虑和测试 extractWords(),并对其进行分区。使用涉及网页内容的测试分区可能是合理的,因为程序中实际上就是这样使用 extractWords()的。 但不要在测试用例中实际调用 getWebPage(),因为 getWebPage() 可能会出现错误!相反,将网页内容存储为字面字符串,然后直接传给 extractWords()。这样你就可以编写一个独立的单元测试,如果测试失败,你可以更确信错误出在实际测试的模块 extractWords() 中。
请注意,makeIndex() 的单元测试不能轻易地以这种方式隔离开来。 当测试用例调用 makeIndex() 时,它不仅要测试 makeIndex() 内部代码的正确性,还要测试 makeIndex() 调用的所有方法的正确性。如果测试失败,错误就可能出现在这些方法中的任何一个。这就是为什么我们要对 getWebPage() 和 extractWords() 进行单独测试,以增加我们对这些模块的信心,并将问题定位到将它们连接在一起的 makeIndex() 代码上。
如果我们为 makeIndex() 所调用的模块编写 存根 (stub) 版本,就可以隔离像 makeIndex() 这样的高级模块。例如,getWebPage() 的存根根本不会访问互联网,而是返回模拟的网页内容,无论传递给它的 URL 是什么。 类的存根通常被称为 模拟对象 。 存根是构建大型系统时的一项重要技术,但我们在 6.005 中一般不会使用存根。
自动测试和回归测试
没有什么比完全自动化更容易运行测试,也更有可能运行测试了。自动化测试是指自动运行测试并检查其结果。测试驱动程序不应是一个交互式程序,提示输入并打印出结果,让你手动检查。相反,测试驱动程序应在固定的测试用例中调用模块本身,并自动检查结果是否正确。测试驱动程序的结果应该是 “所有测试都 OK” 或 “这些测试失败:…”。一个好的测试框架(如 JUnit)可以帮助你构建自动化测试套件。
请注意,像 JUnit 这样的自动测试框架可以让您轻松运行测试,但您仍然需要自己编写优秀的测试用例。自动测试生成是一个难题,目前仍是计算机科学研究的热点。
一旦实现了测试自动化,在修改代码时重新运行测试就非常重要了。这可以防止程序 回归 (regressing),即在修复新错误或添加新功能时引入其他错误。在每次更改后运行所有测试称为回归测试 (regression testing)。
每当您发现并修复了一个错误,就把引起错误的输入作为测试用例添加到您的自动测试套件中。这种测试用例称为 回归测试。 这有助于用好的测试用例填充测试套件。请记住,如果一个测试引出了错误,那么它就是好测试,而每个回归测试都会在一个版本的代码中引出错误!保存回归测试还能防止重新引入错误的还原。这个错误可能很容易犯,因为它已经发生过一次了。
这种想法也导致了 测试优先的调试 (test-first debugging)。当出现错误时,立即编写一个测试用例,并立即将其添加到测试套件中。一旦发现并修复了错误,所有的测试用例都将通过,调试工作也就完成了,同时也就有了针对该错误的回归测试。
在实践中,自动测试和回归测试这两个概念几乎总是结合在一起使用。回归测试只有在测试可以经常自动运行的情况下才是实用的。反过来说,如果您的项目已经有了自动化测试,那么您不妨使用它来防止错误回归。因此,自动回归测试是现代软件工程的最佳实践。
总结
在这篇阅读材料中,有以下要点:
- 测试优先编程。在编写代码之前先编写测试。
- 系统地选择测试用例的分区和边界。
- 使用白盒测试、检查语句覆盖率,以完善一个测试套件。
- 尽可能孤立地对每个模块进行单元测试。
- 自动回归测试,防止错误再次出现。
今天的阅读材料与优秀软件的三个关键特性的关联:
- 远离 Bugs。测试是为了发现代码中的 Bugs,而测试优先编程则是为了在引入错误后尽早发现它们。
- 易于理解。在这一点上,测试的帮助不如代码审查的帮助大。
- 为变更做好准备。编写仅依赖于规范中行为的测试为变更做好了准备。我们还谈到了自动回归测试,它有助于防止代码更改后再次出现错误。